BioStat
Avec BioStat, accédez à une gamme complète d'outils de statistiques et des méthodes d'analyses graphiques particulièrement faciles d'utilisation grâce à une interface simple et intuitive. BioStat v5 est un outil professionnel complet d'analyse statistiques dédié à la biologie et la médecine, mais l'interface est tellement simple que même une personne sans aucune formation en statistiques peut l'utiliser pour traiter des données, à partir d'instructions simples et d'une connaissance de base de l'utilisation d'un PC.

Un processeur puissant de feuilles de calculs
Standalone version reads numerous text formats, Microsoft* Excel* 97-2003 (XLS) and 2007-2021 (XLSX) workbooks, SPSS* Documents and supports almost all Excel built-in worksheet functions (math, statistical, financial). New version comes with Excel add-in with all the BioStat features available.
Statistics
BioStat allows to perform various types of analysis - basic statistics and tables, ANOVA, regression analysis, non-parametric statistics, survival and power analysis. Analysis results are written into new worksheet and could be easily edited or exported.
Vous cherchez plus?
StatPlus includes all the BioStat features and even more: design of experiment, time series analysis and forecasting, control charts for quality control. StatPlus comes as both standalone spreadsheet and Excel add-in, and works on Windows and Mac OS.
En savoir plus sur StatPlus pour Windows ou StatPlus:mac.
Essayez gratuit
We have free trial that gives you an opportunity to evaluate the software before you purchase it. Should you have any questions during the trial period, please feel free to contact our Support Team.
Abordable
You will benefit from the reduced learning curve and attractive pricing while enjoying the benefits of precise routines and calculations. License is permanent, there is no renewal charges.
Exigences système
Requiert Windows 2000 ou supérieur. Prend en charge Windows 11 et Excel 2021.
Captures d'écran


Liste des fonctionnalités
- Caractéristiques Pro
- Tableur intégré rapide et puissant.
- Compagnon de tableur (add-in) pour Excel 2007-2021.
- Support prioritaire.
- La licence est permanente. Mises à jour majeures gratuites pendant la période de maintenance.
- Statistiques de base
- Statistiques descriptives détaillées.
- Test t pour un échantillon.
- Test t pour deux échantillons.
- Méthodes pour données résumées.
- Test de Fisher d'égalité de deux variances.
- Test Z pour un échantillon et test Z pour deux échantillons.
- Analyse de corrélation et covariance.
- Tests de normalité (Jarque-Bera, Shapiro-Wilk, Shapiro-Francia, Cramer-von Mises, Anderson-Darling, Kolmogorov-Smirnov, D'Agostino's tests).
- Tableau de contingence et test du Khi-deux.
- Tables de fréquences (tris à Plat) pour les variables discrètes et continues).
- Définitions multiples pour le calcul de quantiles.
- Analyse de variance (ANOVA)
- ANOVA à un facteur, ANOVA à deux facteurs (avec et sans interactions).
- ANOVA à trois facteurs.
- Comparaisons multiples (post-hoc) - Bonferroni, Tukey-Kramer, Tukey B, Tukey HSD, Neuman-Keuls, Dunnett.
- ANOVA à mesures répétées et modèles mixtes.
- Analyse multivariée
- Analyse en composantes principales (ACP ou PCA).
- Analyse factorielle (FA).
- Analyse discriminante (DA).
- Clustering hiérarchique et K-Means.
- Statistiques non-paramétriques
- Analyse des tableaux de contingence 2x2 (test du khi-deux, khi-deux de Yates, test exact de Fisher, etc.).
- Rang et centile.
- Test du Khi-deux.
- Corrélations des rangs (Tau de Kendall, Rho de Spearman, Gamma, Fechner).
- Comparaisons d'échantillons indépendants.
Test U de Mann-Whitney, test de Kolmogorov-Smirnov, test des suites de Wald-Wolfowitz, test de Rosenbaum. Test de Kruskal-Wallis (ANOVA de Kruskal-Wallis par rangs), test des médianes (test de Mood). - Comparaisons d'échantillons dépendants.
Test des rangs signés de Wilcoxon, test des signes, ANOVA de Friedman, W de Kendall (coefficient de concordance de Kendall). - Test Q de Cochran.
- Régression
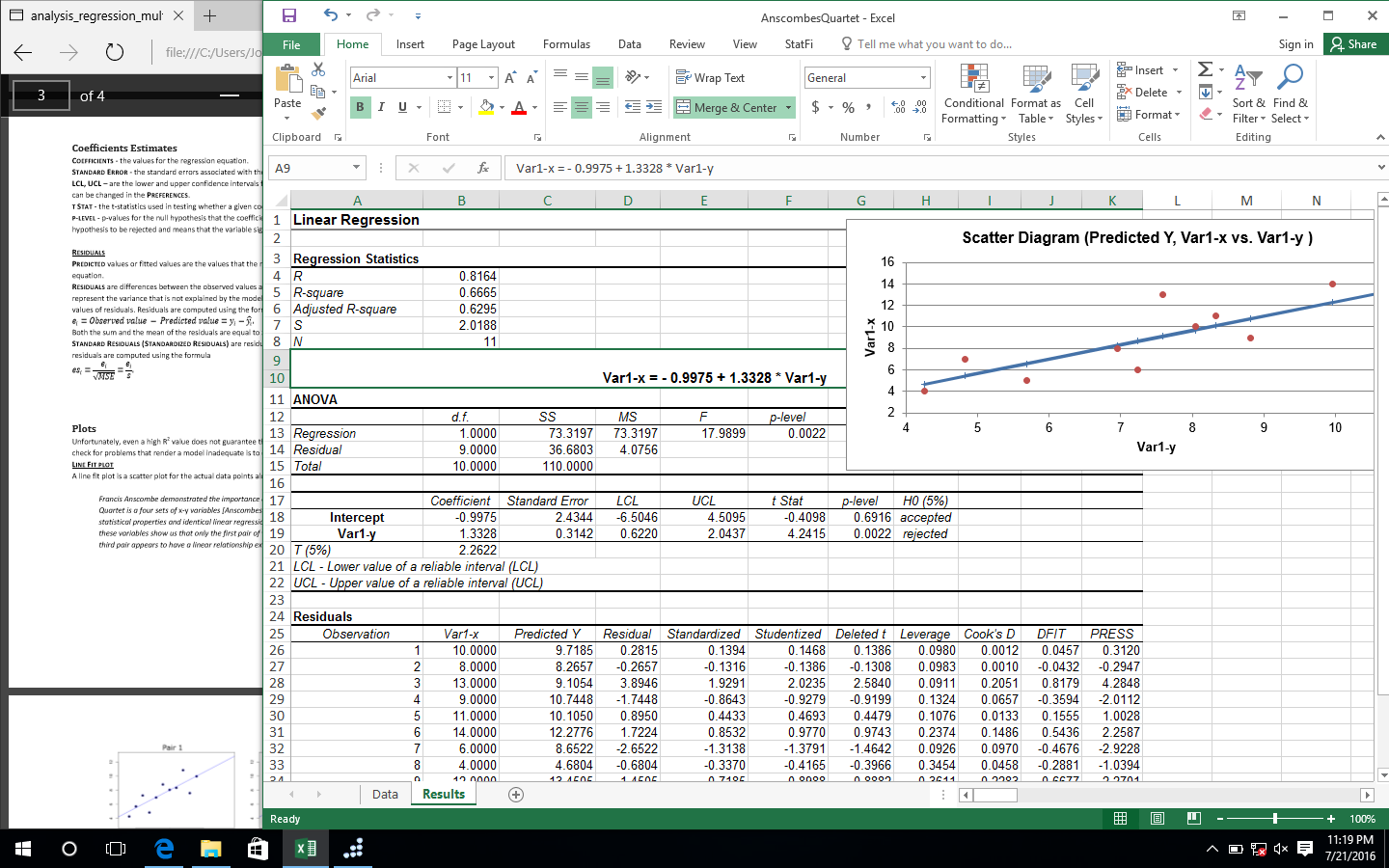
- Régression linéaire (analyse des résidus, diagnostics de colinéarité, bandes de confiance et de prévision).
- Régression pondérée (WLS).
- Régression logistique binaire.
- Régression pas à pas (stepwise) - ascendant et descendant.
- Régression polynomiale.
- Estimation de courbe.
- Tests d'hétéroscedasticité (test de Breusch–Pagan, test de Harvey, test de Glejser, test de ARCH de Engle, test de White).
- Analyse de survie
- Tables de survie.
- Analyse de survie de Kaplan-Meier (le test du logrank, rapport de hasards - hazard ratios).
- Régression de Cox (modèle à risque proportionnel).
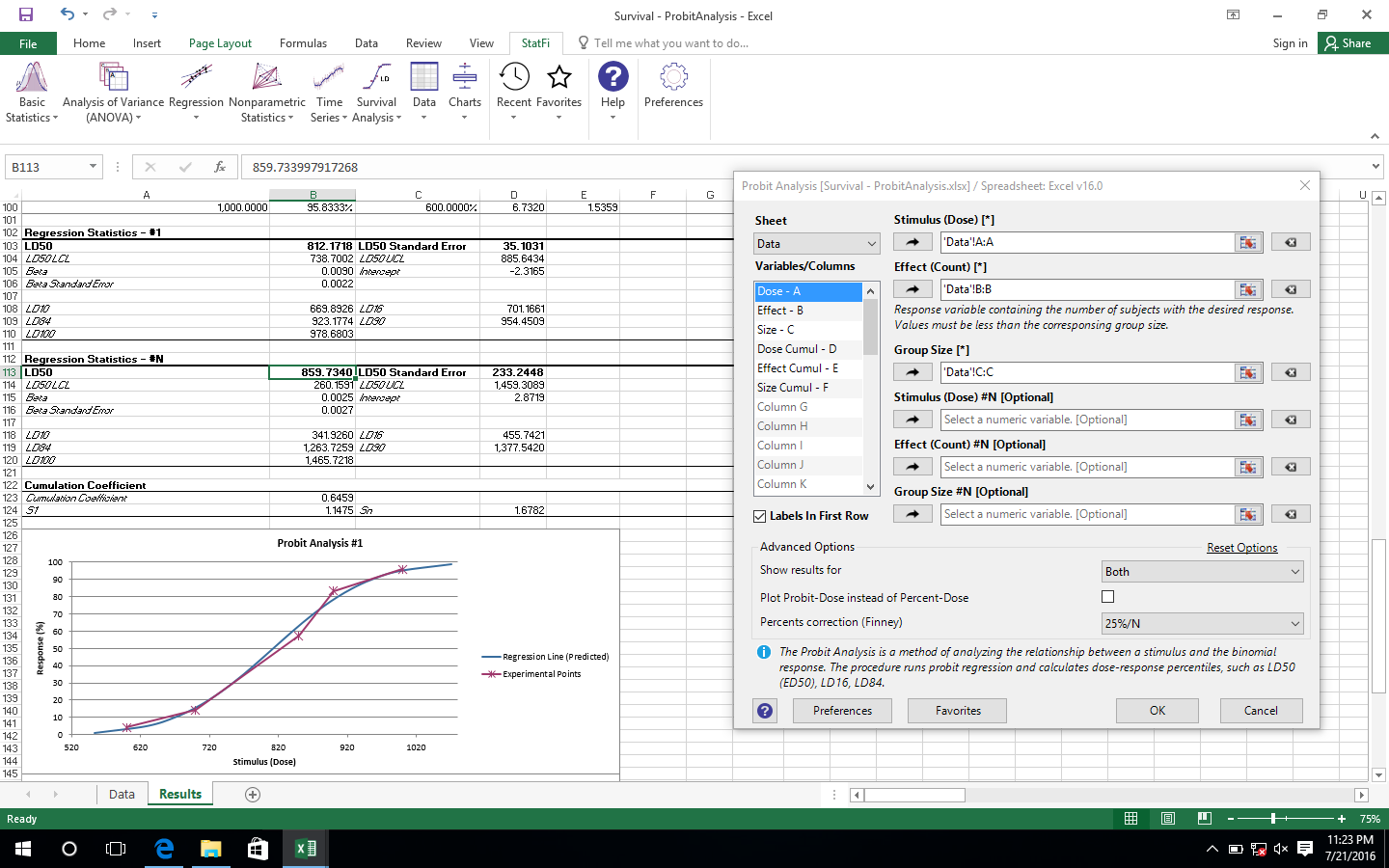
- Analyse par la méthode des probits (Finney et LPM).
Valeurs LD (LD50/ED50 et autres), calcul du coefficient cumulatif. - Analyse ROC (fonction d’efficacité du récepteur).
Les méthodes pour calculer AUC (aire sous la courbe ROC) - DeLong's, Hanley et McNeil's. Le rapport comprend: AUC (with confidence intervals), coordonnées de la courbe ROC, indicateurs de performance - sensibilité et spécificité (avec intervalles de confiance), valeurs prédictives positives et négatives, J de Youden (l'indice de Youden), précision et rappel. - Comparer des courbes ROC.
- Transformation de données
- Echantillonnage de données (aléatoire, périodique, conditionnel).
- Génération de nombres aléatoires.
- Standardisation.
- Empiler/désempiler les colonnes.
- Opérations sur les matrices.
- Graphiques statistiques
- Histogramme
- Diagramme en nuage de points.
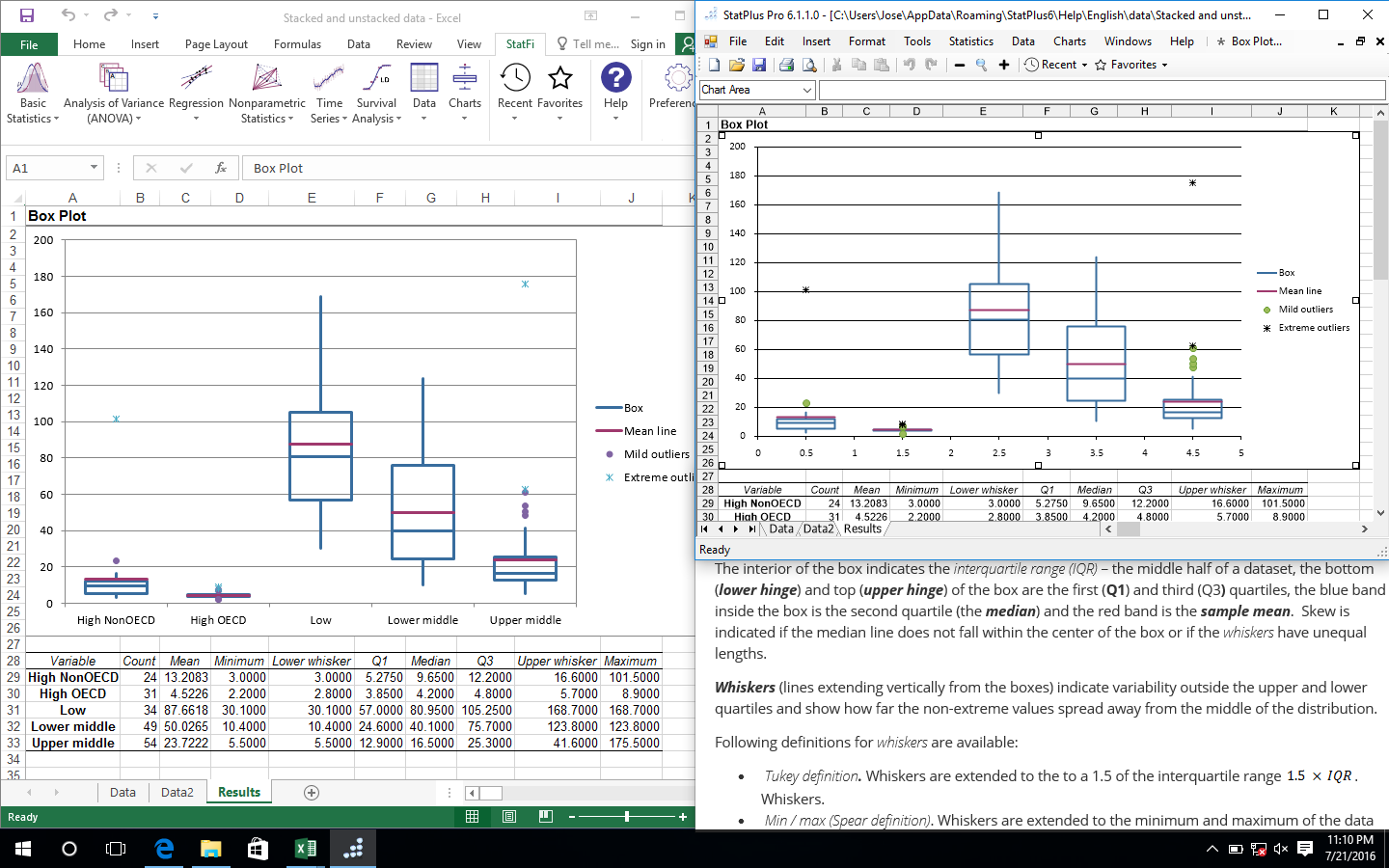
- Diagramme boîte à moustaches (box-plot).
- Diagramme branche-et-feuille.
- Graphique de Bland-Altman.
- Graphique de Bland-Altman avec plusieurs mesures par sujet.
- Diagrammes quantile-quantile Q-Q pour différentes distributions.
- Mise à niveau vers StatPlus pour obtenir plus:
- Analyse des séries temporelles
- Transformation de Fourier rapide.
- Analyse des séries interrompues.
- Lissage exponentiel.
- Moyenne mobile.
- Autocorrélation et autocorrélation partielle (ACF et PACF).
- Tests de racine unitaire - Dickey–Fuller, Augmented Dickey–Fuller (ADF), Phillips–Perron, Kwiatkowski–Phillips–Schmidt–Shin (KPSS).
- Cartes de contrôle - X-bar, R-chart, S-chart, I-MR chart, P-chart, C-chart, U-chart, CUSUM-chart.
- Multi plateforme
- StatPlus est disponible pour PC, Mac et iOS.
Les versions PC et Mac incluent une feuille de calcul intégrée et un complément Excel (add-in). - Bêta: version en ligne.
- StatPlus est disponible pour PC, Mac et iOS.
- En savoir plus sur StatPlus pour Windows ou StatPlus:mac. Si vous possédez déjà une licence BioStat - cliquez ici pour mettre à jour.
- Analyse des séries temporelles

